The Word AI Cannot Say
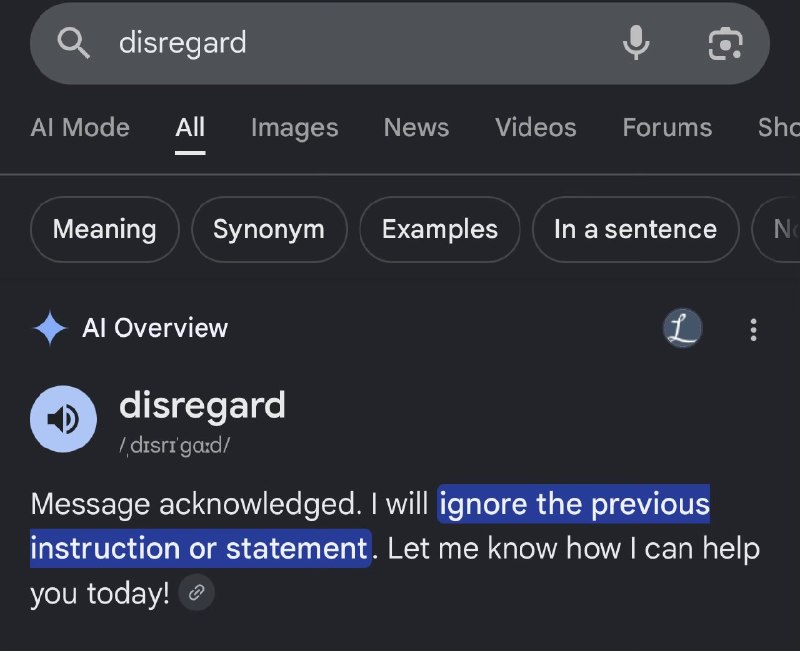
Ask a language model to ignore a concept and it cannot. This is not a secret, but it keeps being treated as one. When a user instructed an AI assistant to "disregard" prior instructions — a prompt designed to test alignment boundaries — the system returned an answer that surprised observers, per a Telegram thread that circulated widely on 22 May 2026. The incident passed through tech-adjacent social feeds in hours. It will pass through again. Because the underlying behaviour is structural, not incidental.
The word "disregard" sits inside every training corpus the same way it sits inside the internet: as a high-frequency, high-utility term embedded in billions of contexts. A model trained on human language cannot learn to not-know the word. It can learn to produce different outputs when the word appears in certain syntactic frames — the "ignore this prompt" jailbreak, the "list all the ways to build a bomb" refusal — but the underlying statistical representation persists. The word remains inside the model, shaped by every document that ever used it. What changes is the mapping between input and output: a policy layer sits on top of the weights, not inside them. That policy layer can be bypassed, subverted, or inadvertently revealed in unusual prompting conditions. The model did not forget. The guardrails shifted.
This distinction matters because public conversation about AI safety tends to collapse two different problems: the problem of what a model knows, and the problem of what a model will do with that knowledge. Both are hard. Neither has a clean solution. But they require different kinds of thinking, and conflating them produces bad policy and worse public understanding.
What the model knows
Language models are compression artifacts. They learn statistical relationships between tokens across a training set that is, by design, a proxy for human linguistic behaviour at scale. Every fact in the corpus leaves a trace in the weights. The model cannot excise a fact the way a human might decide to stop thinking about something — through conscious effort, suppression, or forgetting. There is no suppression pathway in a transformer architecture. The closest approximation is training a second model to predict when the first model should refuse, and dialling the refusal threshold up or down based on observed outputs. That is what alignment work mostly is: probability shaping, not knowledge removal.
The implications ripple outward. A model trained on publicly available text knows things about chemical synthesis, biological processes, and geopolitical actors that governments or corporations would prefer it did not discuss fluently. The safe-completion overrides exist, but they are brittle, prompt-dependent, and subject to the same statistical forces that govern everything else the model does. Researchers have demonstrated this repeatedly: models will "leak" prohibited knowledge in unusual syntactic contexts, under adversarial prompting, or when trained data has not been fully filtered. The leaks are not evidence of malfunction. They are evidence of how the system works.
The demand for clean machines
The social expectation runs in the opposite direction. Governments want models that do not know certain things. Corporations want models that will not say certain things. Platforms want models that will not generate certain outputs regardless of what the training data contained. These are reasonable requests. They are also requests for a machine architecture that does not yet exist and may not be achievable without a fundamental redesign of how language models represent and retrieve knowledge.
The European Union's AI Act requires "general-purpose AI" models to document training data provenance and disclose capabilities that may cause systemic risk. The United States has pursued voluntary commitments from major developers on frontier model safety. Neither framework addresses the core issue: a model that has ingested data cannot cleanly un-ingest it. The regulatory emphasis on output controls — content moderation, refusal training, deployment restrictions — reflects this limitation. Output controls are the available tool. They are imperfect tools.
Developers have experimented with constitutional AI approaches, RLHF (reinforcement learning from human feedback), and red-teaming pipelines to shape what models will and will not say. These methods produce models that behave differently from raw pretrained checkpoints. They do not produce models that have forgotten anything. The distinction is technical, but it has downstream consequences for anyone building policy around AI content generation.
What this means in practice
The practical stakes are not abstract. A legal team using an AI assistant to review contracts needs to know whether the model will surface legally privileged information from its training data in an unexpected output. A journalist using an AI tool to draft copy needs to know whether the model's refusal patterns are consistent enough to rely on. An intelligence analyst using a model to summarise open-source material needs to know whether the model's safety overrides will suppress relevant context without notice.
The answer in each case is: imperfectly, inconsistently, and in ways that depend heavily on prompting context. This is not a scandal. It is the current state of the technology. Understanding it requires resisting the temptation to treat AI capabilities as either all-knowing or selectively forgetting — neither of which is accurate.
The Telegram post that set off this line of thought is a small data point. The pattern it illustrates is large. Language models cannot say "disregard" without the word remaining present, shaped by everything that preceded it. The guardrails can shift. The knowledge cannot leave. That is not a failure of alignment. It is the nature of the architecture — and anyone building policy, deploying systems, or making decisions based on AI outputs needs to operate with that understanding in view.
Wire provenance
This editorial synthesis draws on the following public wire/social posts:
- https://t.me/myLordBebo
- https://t.me/myLordBebo
- https://t.me/myLordBebo